In a too high share of the E-commerce targeted SEO processes I work at, and independently of the size, products types or CMS, there’s this list of very common technical and content related search optimization issues shared among them, that harm their capacity to effectively rank for their meaningful relevant queries in a non-trivial way.
Let’s go through them, see how they happen and most importantly, how to fix them:
- Poorly Linked Sub-Categories, Faceted Pages and Products with Search Demand
- To Block or Noindex Meant to be Crawled and Index sub-categories and faceted Pages with Search Demand
- To Index Internal Search Results that cannibalize the site categories/sub-categories/facet Pages
- Category and sub-categories pages with very little, non-unique, differentiated content
- Product pages with very little, non-unique content that don’t get into the index and/or cannibalize each other
- Highly Dynamic Product Pages returning errors or inconsistent status based on its inventory stage
1. Poorly Linked Sub-Categories, Faceted Pages and Products with Search Demand
You want any pages from your online store that are meant to be indexed and ranked, independently from where they’re in the Web structure, to be effectively linked so they can be found by search engines as well as receive internal link popularity, especially if they’re category/facet/product pages that are targeting queries that have non-trivial search volume and are competitive: they should be prioritized to be linked even more prominently.
If your online store is not small, you also want to do this while not wasting your site crawl budget, making sure that those pages that are the ones meant to be indexed and ranked are always crawled as soon as they’re updated, and not left out your site crawl due to reaching limits by referring to other URLs that are not really meant to be indexed nor ranked, and shouldn’t have been internally linked nor included in XML sitemaps.
Unfortunately, is common to find online stores that don’t properly link their sub-categories, faceted pages or products URLs that are meant to be indexed and ranked, in some cases to pages that have a non-trivial search demand (and with enough product supply), and should be prioritized accordingly.
This is happens across different scenarios, one of the top ones being with Web platforms relying on non-crawlable JS based navigation for their second level categories forward or when linking to all facets.
You can quickly spot this issue by browsing the different type of pages without JavaScript enabled (you can use Chrome’s Web Developer extension) and see how much of the navigation is truncated without it:
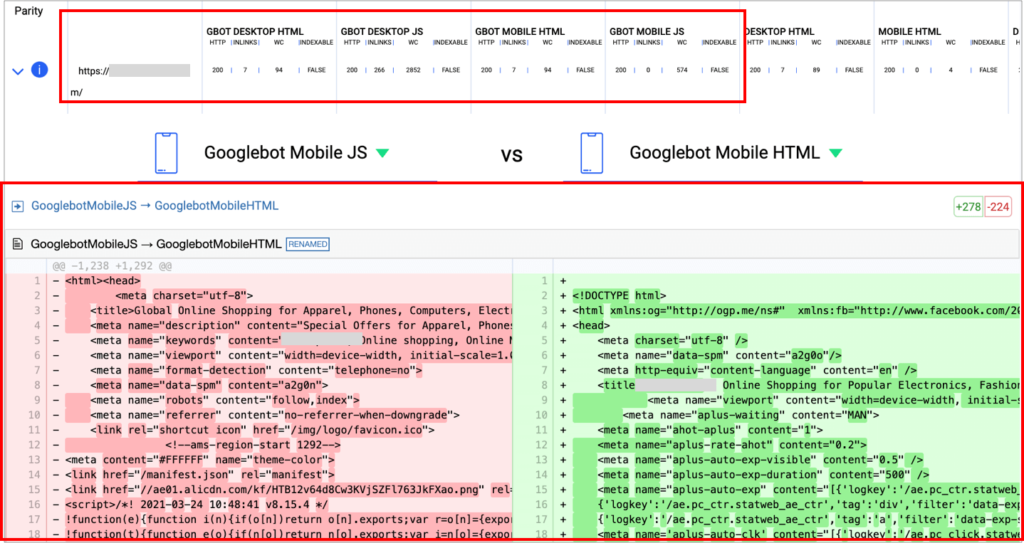
Double check what’s shown in the rendered DOM vs. the raw HTML in both mobile and desktop for free too with iPullrank’s Parito tool, that allows you to easily compare the code between the different versions to spot the differences. Here you can also identify if these links are implemented via client side rendered JS while using <a href> tags or not, making them non-crawlable.
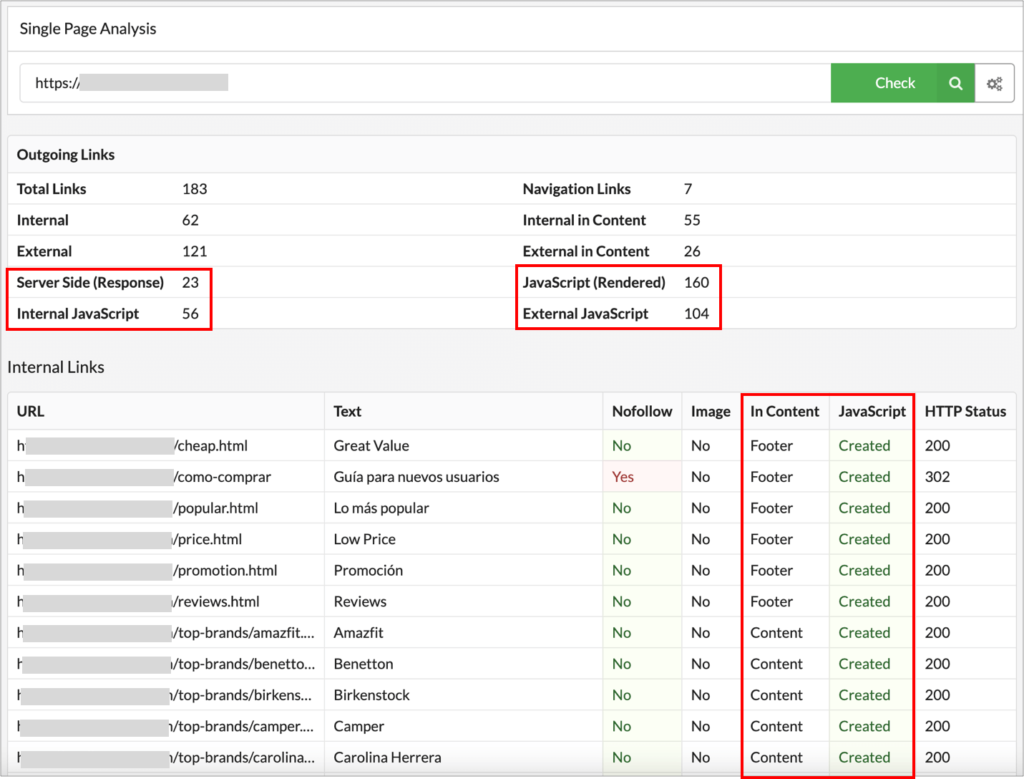
If you identify gaps and need to dig deeper to understand exactly which are all the links relying on client side rendered JS and how they’re implemented, use Sitebulb’s single page analysis that will directly show you the number of links of any page and how they’re generated, if found in the raw HTML or if they’ve been created or modified in the rendered one, if they’re going to internal or external pages, with a list of the URLs and anchor text used in each.
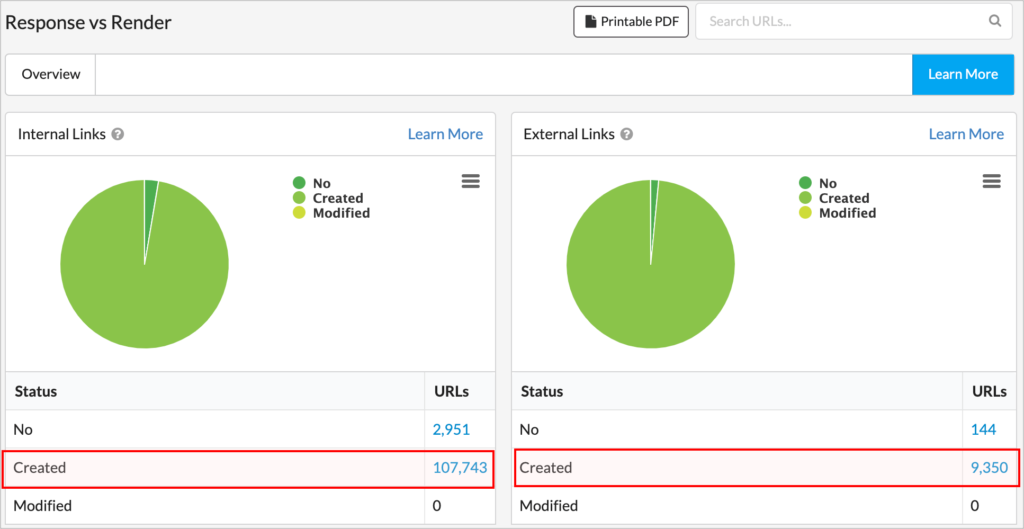
Besides validating the different types of pages of the site, when non-trivial gaps are found, it’s highly advisable to do a full crawl to compare the internal links found in the response vs. the rendered HTML, to make sure you don’t leave anything important out. This is provided by default by some SEO crawlers like Sitebulb when crawling with JS enabled, but if you don’t have access to one, you can always do a crawl with JS enabled and another without, to spot all the different levels of the site with the differences.
After identifying which are those links relying on client side rendered JS and if they’re crawlable or not, verify how they’re rendered by using the URL inspection tool from the Google Search Console or alternatively, the Mobile Friendly Test, as there might be time-outs, resource blocking issues, etc. that could be also not allowing Google to effectively render the JS reliant links (and content).
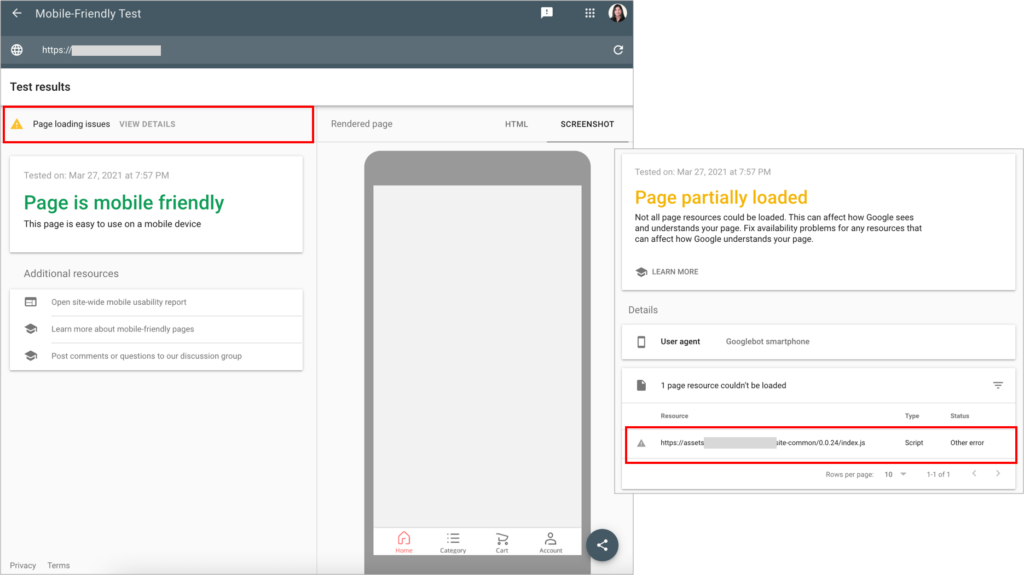
Another common scenario that causes to poorly link to important categories/sub-categories/facets/products URLs is the practice to add parameters to navigation links with the goal to track their clicks, that end up causing that navigation links go to non-canonical URLs versions of the pages, as shown in the example below.
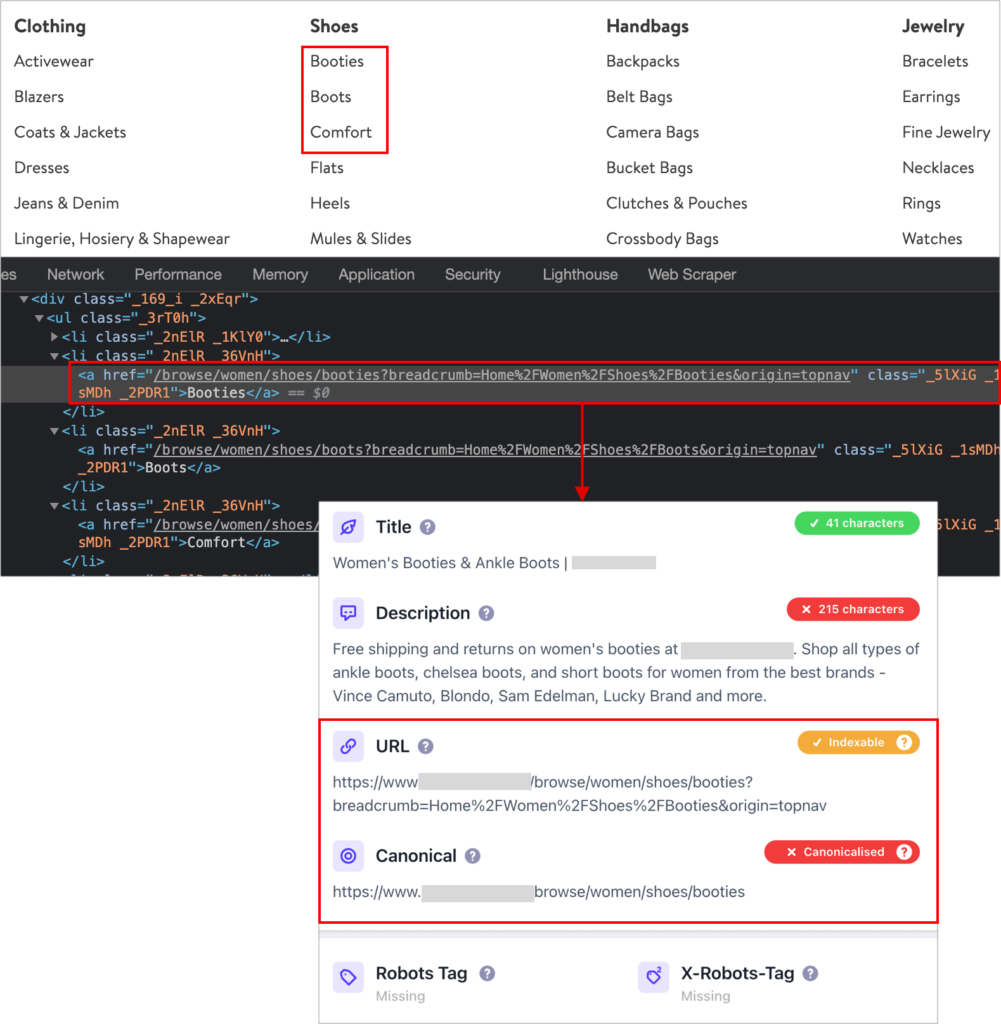
This practice is also one of the usual culprits for having a too high share of crawled but excluded URLs from the Google index categorized as “alternate page with proper canonical tag”.
You can double check the sample URLs with parameters featured in the Coverage Report as excluded due to this reason using the URL inspection feature, where you can see if the Google-selected canonical is the same URL without the parameter that you specified, and is a matter of avoid linking/referring to this non-canonical URL version from within the navigation and XML sitemaps that you’re generating by tagging your internal links.
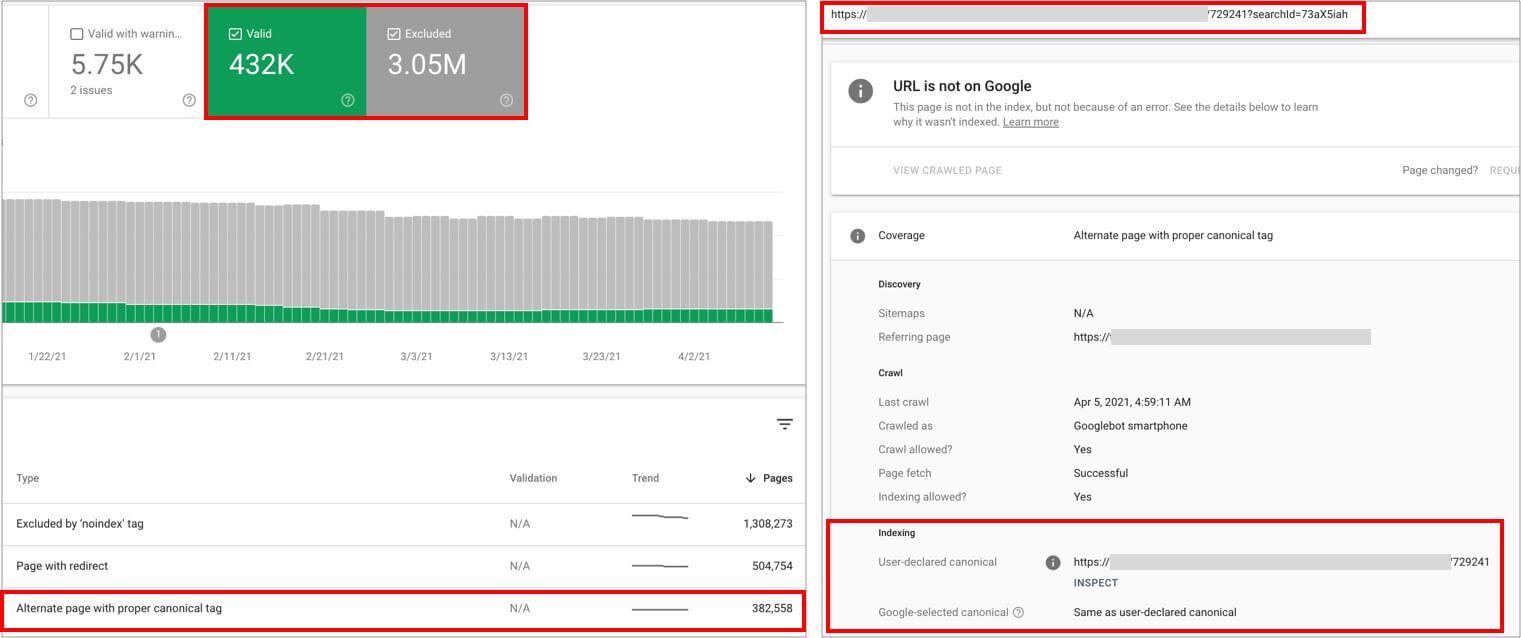
You can also easily check if you suffer from this issue by crawling your site with your own SEO crawler and segment the different types of pages, verifying how many of the crawled URLs of each type are indexable or not, and the reason for their lack of indexability: If they’re canonicalized to others, noindexed, etc. and from where these canonicalized URLs versions are being linked from within the site.

If you find that your online store navigation is relying on non-crawlable/non-rendered links to refer to subcategories/facets/products pages, it’s then important to update their implementation to make sure that the navigation is updated/changed to use crawlable links, ideally links that don’t rely on Google’s capacity to render client side JS, and that are server side rendered.
Something similar if you find to be linking to non-canonical URLs versions of these pages, it’s then important to start doing it so to their canonical ones, replacing the usage of parameters to track their activity with other methods as the ones described here.
Sometimes this cannot be done as fast as you would need due to technical resources/flexibility, if this is the case, then is important to prioritize to fix those areas/pages that are already important to your site organic search traffic and could bring you even more if they were properly linked, as well as those that have the highest search potential to bring you the most too.
To identify these “poorly linked” indexable pages to prioritize to link further you can use your SEO crawler by integrating also organic search traffic data. Many SEO crawlers will integrate with Google Analytics and Search Console data and will allow you to see which are those indexable pages, attracting already non-trivial traffic with less internal links, as Ryte allows you to do, also showing the number of “clicks from the home page” of each page.
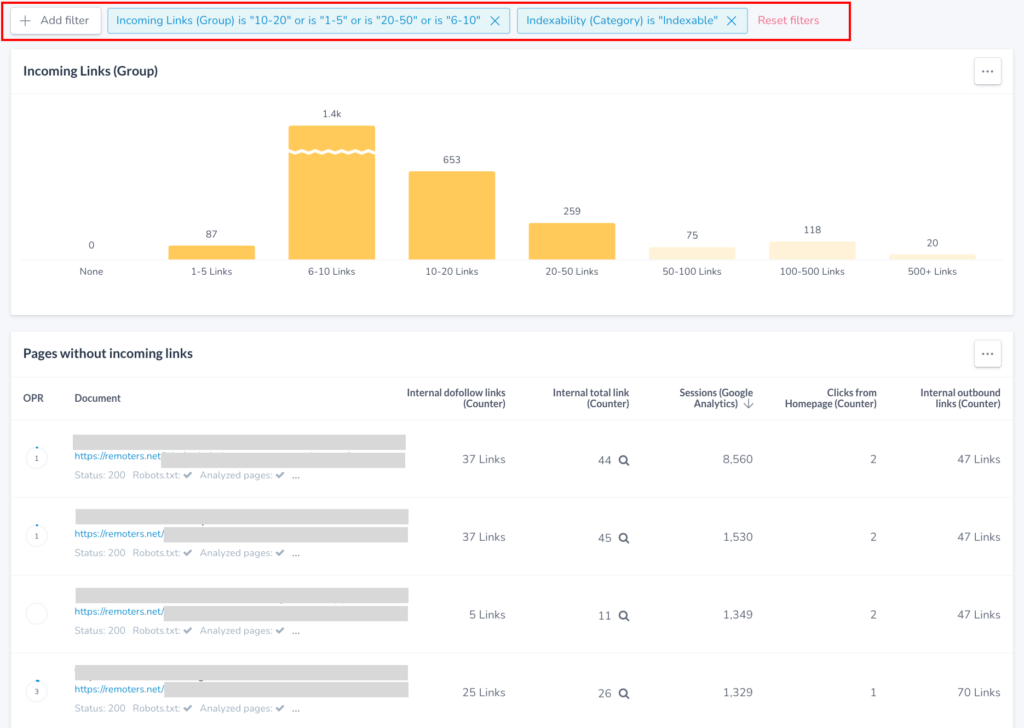
You can also create your own “internal link analysis sheet” by aggregating more data sources to make sure to not leave anything out, for example, along your pages indexability, internal links data and content optimization (via your SEO crawler), aggregating their rankings per URL (query and position that you can find via SEMrush/Sistrix/Ahrefs), as well as clicks and CTR (via Google Search Console) and backlinks (via SEMrush/Sistrix/Ahrefs/Search Console), to identify those pages that can provide you the highest opportunities to start with them.
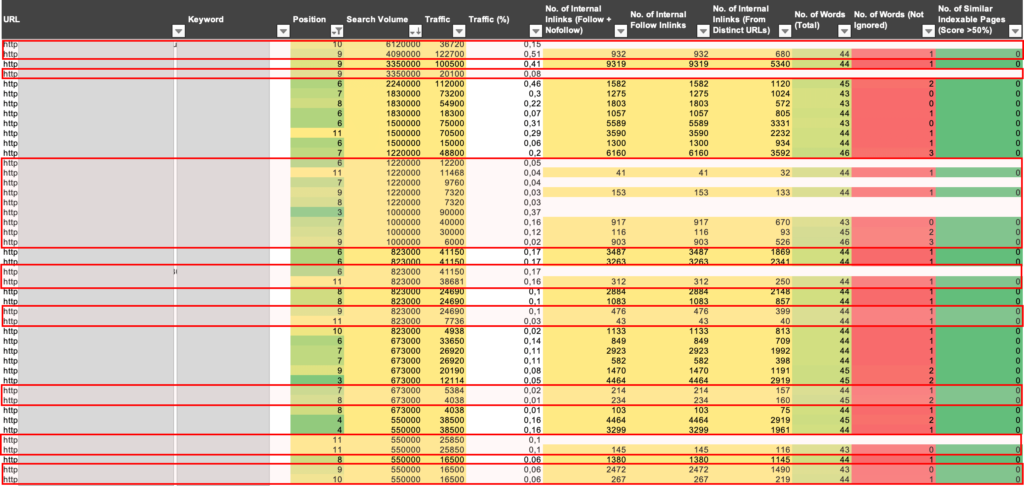
2. To Block or Noindex Meant to be Crawled and Index sub-categories and faceted Pages with Search Demand
Another not so uncommon e-commerce issue is to find meant to crawled sub-categories and faceted pages with search demand… to be blocked. This happens in many cases because of rules set by default to certain types or levels of the Web structure, for example, by disallowing all URLs under 2nd level sub-categories.
The issue with these “generic crawlability rules” is that they don’t take into consideration the search demand that many of these pages have, that are not fulfilled by their parent category that is too broad and for which their products pages are too specific to rank for, and if they do, they will end up cannibalizing each other, without ranking in the best positions.
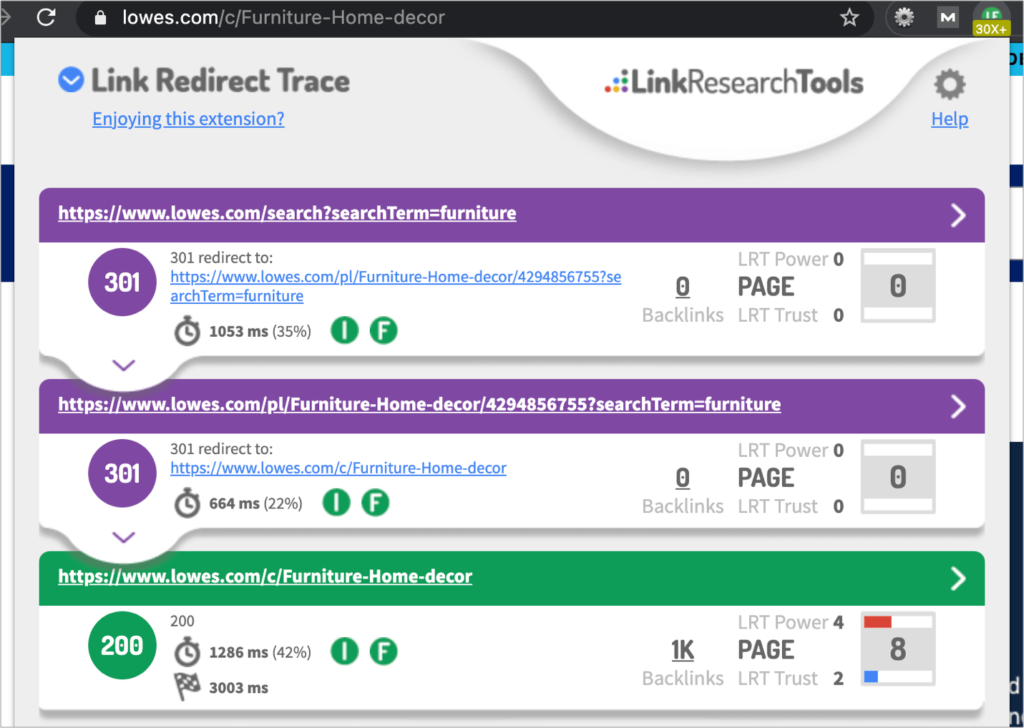
For example, “rose gold wedding rings” has a non-trivial search volume despite being a query that will be typically targeted by a color facet page, but one that in this case would be important to index and rank for. However, we can also see how the faceted page generated at an online jewelry store is not only canonicalized to the parent, first level category page for wedding bands for women, but also blocked via its robots.txt through a disallow to all those types of URLs.
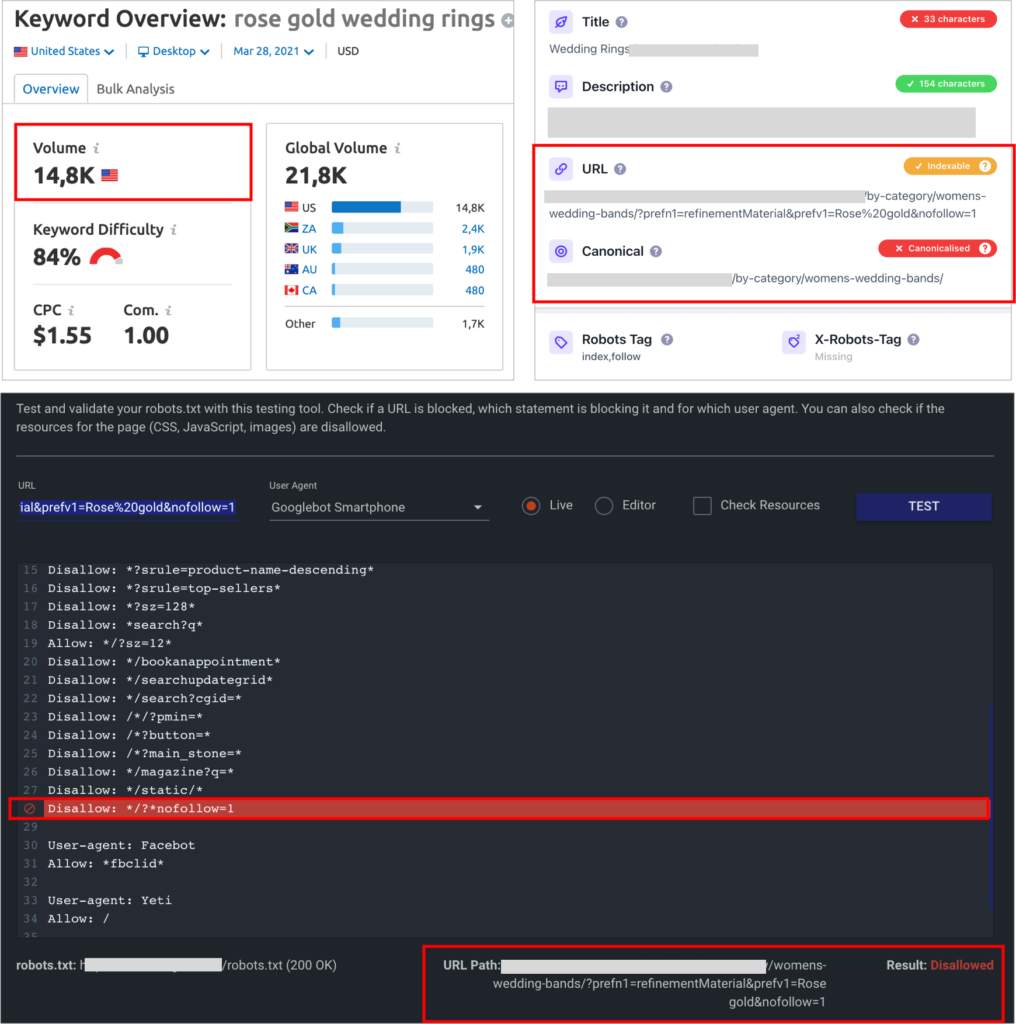
This is not uncommon in online stores to avoid cannibalization issues between sub-categories/facets with main categories, however, it’s important to consider that many of these sub-categories/facets actually target queries that won’t be fulfilled by the too broad parent categories and too specific products URLs.
For example, the “Yeezy Boost 350 Sneakers for Men” term is one of those terms that can be better targeted by a facet page, as there are many types of black shows of this model and brand for men, rather than doing it so with a product URL, that only features a single pair.
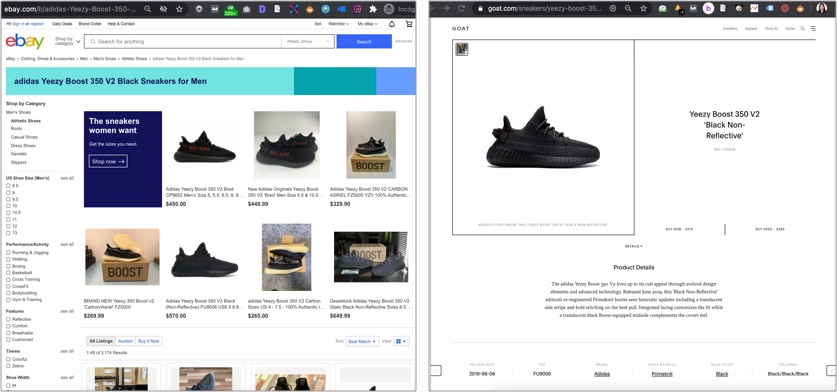
However, it’s not uncommon to find products URLs ranking (although usually not in the best positions) for too broad queries for them, that should have been ranked by facets/sub-categories instead. The issue is that these products URLs end up cannibalizing each other (as there are many products with the same characteristics) and have a short lifecycle, meaning that their URLs will tend to disappear after a few months, and won’t be able to rank as well in a consistent way, as a better linked sub-category or facet page could.
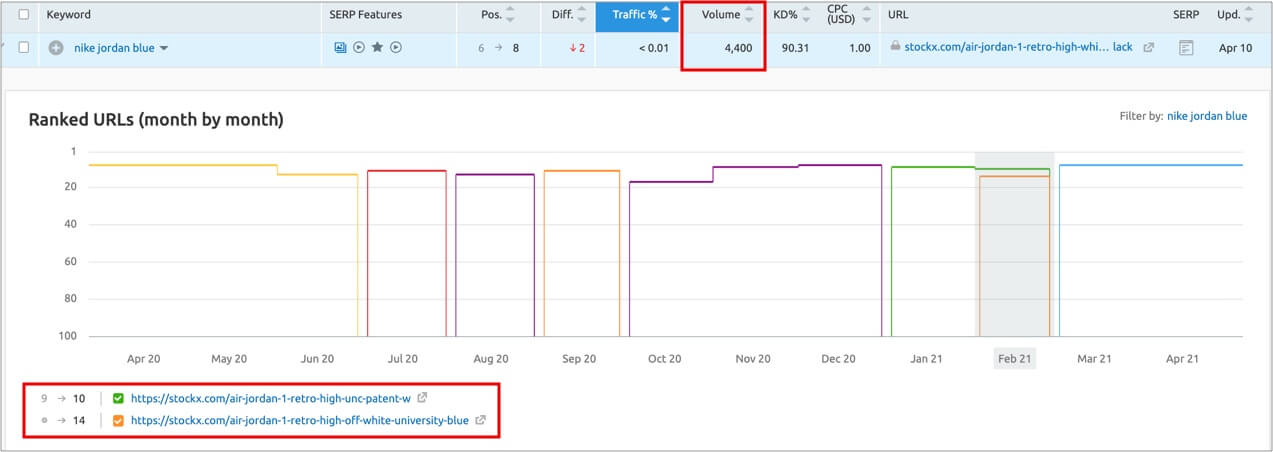
The way to solve this issue it’s to configure sub-categories and facets crawlability and indexability taking into consideration their search demand and supply:
- Demand: Does the sub-category/facet products have non-trivial search volume worthy to target?
- Supply: Are there enough specific products featured in the sub-category/facet to offer to satisfy user need?
Set a minimum for both to start indexing and allowing them to be crawled, and internally link to them accordingly, so they can be easily found and pass internal link popularity consistently to them too.

3. To Index Internal Search Results that cannibalize the site categories/sub-categories/facet Pages
There are also still many e-commerce sites that allow their internal search results to be indexed, in some cases due to thinking that blocking them from being crawled is enough, which is not correct, as Google clarifies in the robots.txt specification “You should not use robots.txt as a means to hide your web pages from Google Search results. This is because, if other pages point to your page with descriptive text, your page could still be indexed without visiting the page. If you want to block your page from search results, use another method such as password protection or a noindex directive.”
This is why one of the basic validations when doing an SEO audit should be to search with the “site:” operator for any internal search result URL to see if they’re indexed:
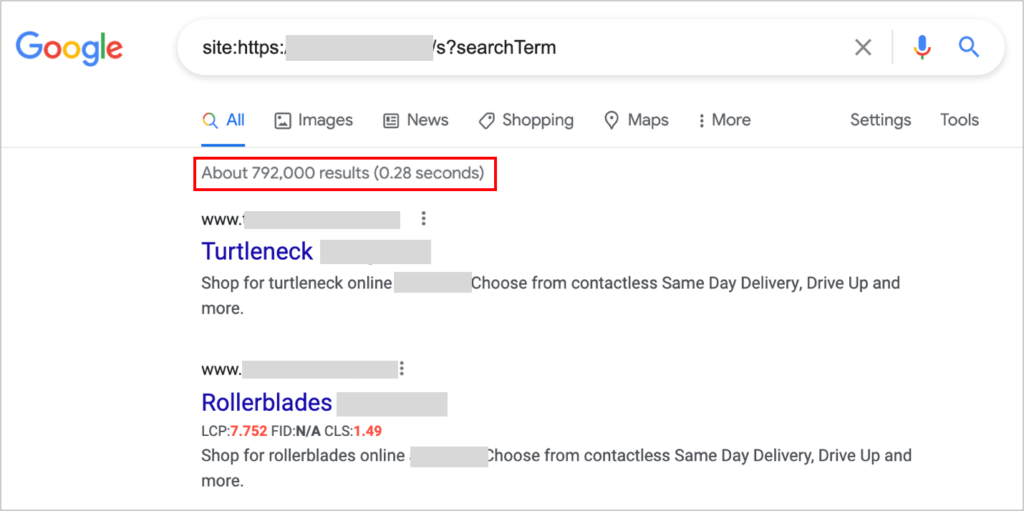
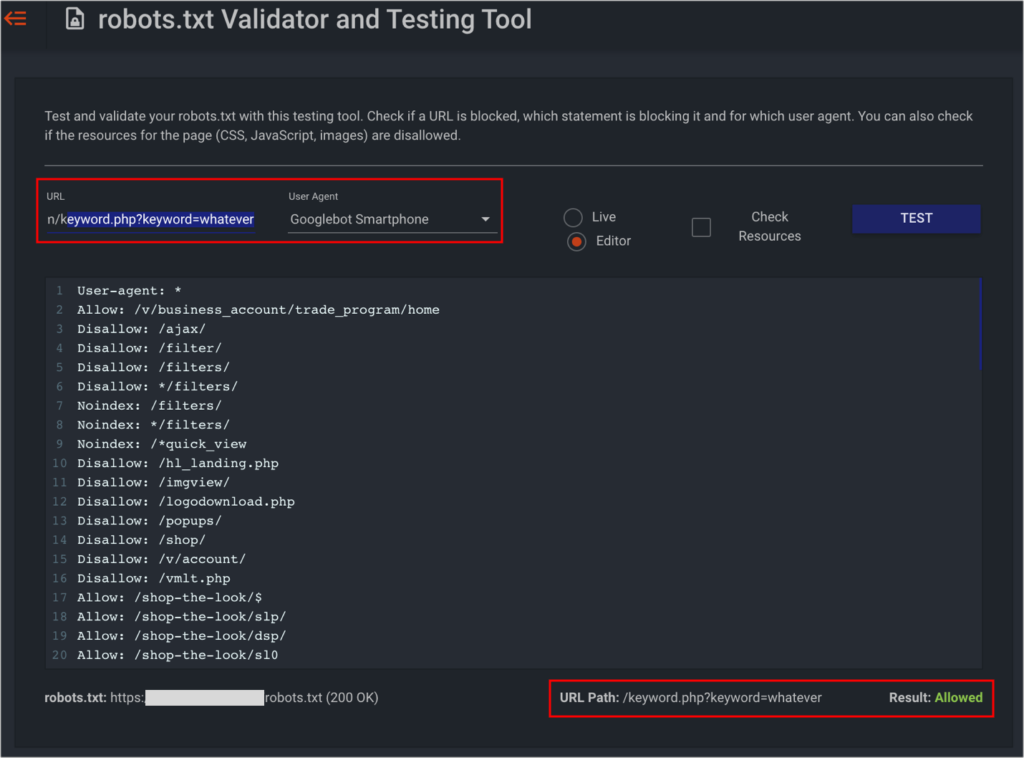
… as well as checking if internal search results URLs also being blocked or not via the robots.txt (for which you can use the Google Search Console robots.txt validator or the TechnicalSEO.com one).
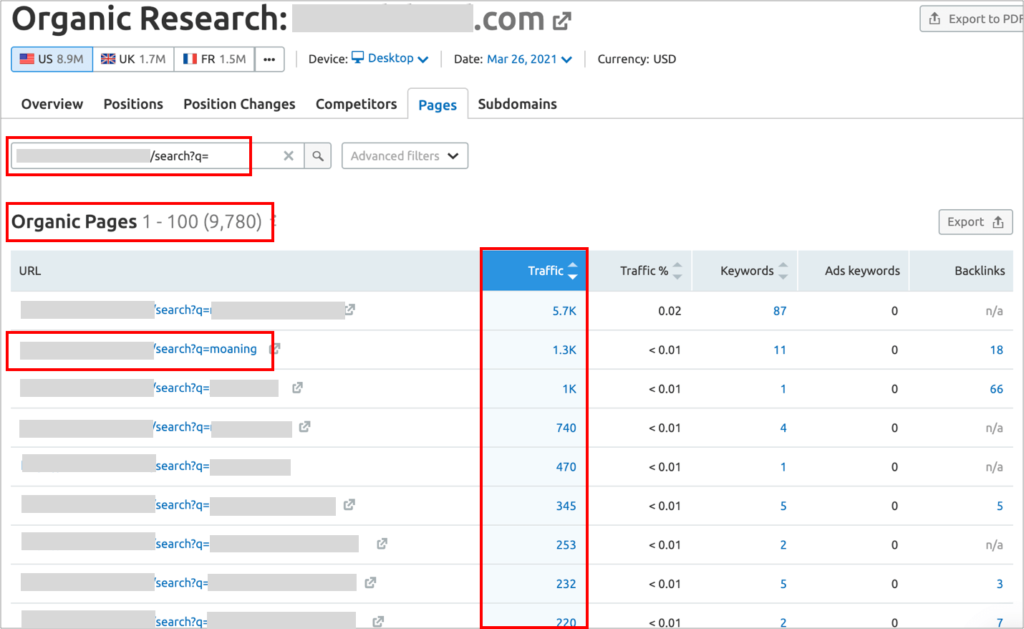
Another validation is to also look for internal search URLs in SEMrush/Sistrix/Ahrefs and your own Google Search Console data to see if these are bringing any rankings, and if these are meaningful to keep (and 301-redirect to the relevant category/sub-category/facets pages that should target them instead)… or if it’s spam and they should be noindexed right away!
In other cases, this is done on purpose with certain rules in place when the Website structure and categorization system doesn’t allow to enable indexable pages to target relevant and important queries, however, it can easily go out of control if there are no strict rules, as there are so many different scenarios that need to be taken into consideration to make sure to index only internal search results pages that…
- Are not yet targeted by already indexed (or meant to be indexed) categories/sub-categories/facets pages
- Have a minimum of relevant products (supply)
- Target relevant queries descriptive of the products with enough search volume (demand)
Additionally, there should be also internal linking rules to make sure that these pages don’t become orphan, and are consistently linked through the relevant levels of the site navigation, to avoid them to become orphan or poorly linked URLs that won’t be able to be effectively recrawled or receive internal link popularity to be competitive.
For example, some e-commerce sites *try* to do this however, when searching for random queries like “aleyda ftw” they end up canonicalizing to a non-existing category page with the searched query:
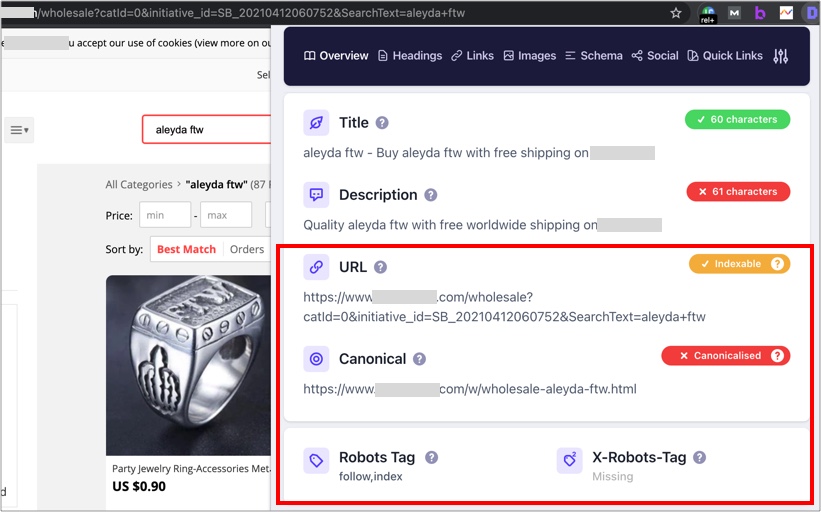
I wouldn’t also recommend to canonicalize internal search results pages to the relevant category ones, as they can end up also consuming too much of the site crawl budget and getting more links than the actual indexable relevant category URL counterpart, making it harder for Google to identify the right “canonical” URL to index for the same content.
An easier and safer way to solve this issue tends to be to noindex by default internal search results pages, while suggesting users searching in the internal search results search box to go to the relevant indexable category/sub-category/facet/product page directly, and if at some point the user end up searching for a topic/query that has a relevant category/sub-category/facet/product page that has been mapped to the internal search result page, to 301-redirect to it directly, rather than keeping the users in noindexed internal search results pages.
It’s also highly recommended to monitor the queries/urls searched through the internal search result feature, to identify those that are relevant and frequently searched, to map them to their relevant indexable category/facet/etc. and if there are not yet indexable categories/facets/etc. for them, that these are enabled to effectively target these terms (and the internal search results can be mapped with them afterwards too).
4. Category and sub-categories pages with very little, non-unique, differentiated content
Although there might be sub-categories or facets pages that are not meant to be indexed nor ranked as they’re targeting queries with very little search volume (little demand) and featuring very little products (little supply), that are not worthy to optimize; in most cases, categories, sub-categories, popular facets, as well as brand pages tend to target some of the most popular *and* commercially driven queries that will bring non-trivial visits from users that are already in the consideration stage of the customer journey, and are critical to optimize.
However, there’s an on-going struggle with e-commerce categories pages content, even if they feature a high number of unique products, as they tend to target transactional oriented queries that many times have a non-trivial search competition, and therefore, need to be highly relevant, well linked and become authoritative to be able to compete for their targeted queries.
This is easier said than done, due to the number of these types of pages on e-commerce sites, and their own commercial nature: they pretty much feature links to products pages, with very little or no additional content at all by default.
In most cases, those that do include content, do it so as an “add-on”, at the bottom of the page, as a tactic to make it relevant to the targeted queries without “messing” with the featured products conversions. The issue is that this content in many cases is also not really aligned with the “commercial” nature of the page.
This issue was confirmed by John Mueller in an interview with Marie Haynes in which he mentioned:
… when the ecommerce category pages don’t have any other content at all other than links to the products then it’s really hard for us to rank those pages. So I’m not saying all of that text at the bottom of your page is bad but maybe 90%, 95% of that text is unnecessary but some amount of text is useful to have on a page so that we can understand what this page is about… The other thing where I could imagine that our algorithms sometimes get confused is when they have a list of products on top and essentially a giant article on the bottom when our algorithms have to figure out the intent of this page. Is this something that is meant for commercial intent or is this an informational page? What is kind of the primary reason for this page to exist and I could imagine that our algorithms sometimes get confused by this big chunk of text where’d we say oh, this is an informational page about shoes but I can tell that users are trying to buy shoes so I wouldn’t send them to this informational page.
So there’s certainly a need to avoid featuring categories/sub-categories/facets pages with only links and almost no content at all, as Google needs to have more information to understand what these pages are about. If you disable your Web browser CSS and images, how much content is still shown in these pages? Sometimes, not really much.
On the other hand, you should also avoid adding too generic, not so relevant text at bottom trying to artificially add relevance to these pages, as their nature/intent won’t be correctly aligned.
For example, the “giant article at the bottom” might seem a bit of an exaggeration if it wasn’t because there are category pages that feature what could be considered entire articles of 1,380 words at the bottom, like this “Apple Watches” category page that includes the evolution of the Apple Watch at the bottom, which is realistically not something that useful at that stage of the user journey:

Instead, e-commerce categories/sub-categories/facets pages should feature content that is aligned with the intent of the user at that stage of the journey, as a salesperson would do already when a customer is already going through products of a certain type at a specific store aisle:
- Confirm to the user what the products they’re looking at are the best at
- Clarify any doubts/concerns regarding the products shared characteristics and usage
- Inform why they’re at the best place to buy these types of products
Here’s a category page example that naturally “blends” its products with content, the New Chapter Vitamins category. The page starts by introducing their vitamins, explaining what makes them better than others “Fermented for maximum absorption”, “Formulated for your specific health needs”, “Support overall health and wellness”, and then after the products featuring a “Quick Q&A”, answering questions like:
- What ingredients are used to make New Chapter vitamins?
- Do I need to take vitamins with food?
- How does New Chapter source their vitamins?
- Is there a difference between taking multivitamins and individual vitamins?
Which are common questions to ask at that stage of the customer journey when buying vitamins.

This type of content is more helpful to satisfy the user intent at this stage of the user journey and should also be easier to generate as the store will tend to have the most common questions/doubts/issues from customers requesting support, so make sure to use this information to develop this content and prioritize their implementation starting with categories/sub-categories/facets targeting more popular queries, so you can see results faster and get more/better support for the rest.
It’s also important to note how this content will pay off in many more ways beyond SEO too: by better highlight the products USPs and supporting the customer decision making / conversion process, all while better highlighting their commercial intent.
For more examples, take a look at Optimizing Content in Category Pages while Keeping its Commercial Nature, where I’ve covered this topic more in-depth.
5. Product pages with very little, non-unique, differentiated content that don’t get into the index and/or cannibalize each other
The lack of unique, relevant content is not only an issue of category/facets pages, but also of products pages, which is only exacerbated by their high number, dynamic nature, and similarity not only with other products on the site but also by featuring in many cases the same “default” description provided by default which can be found in many other online stores that also offer the same product.
This wouldn’t be an issue if it wasn’t because products pages can offer a huge (and sometimes overlooked) opportunity to target and attract a very long tail of queries, which also tend to convert well as they’re searched at the bottom, purchase stage of the customer journey. The aggregated value of products pages can be easily seen by analyzing top e-commerce/marketplaces sites paths, in which we will be able to see how the products directories are usually attracting the highest share of non-branded organic search traffic, as shown in the example below:
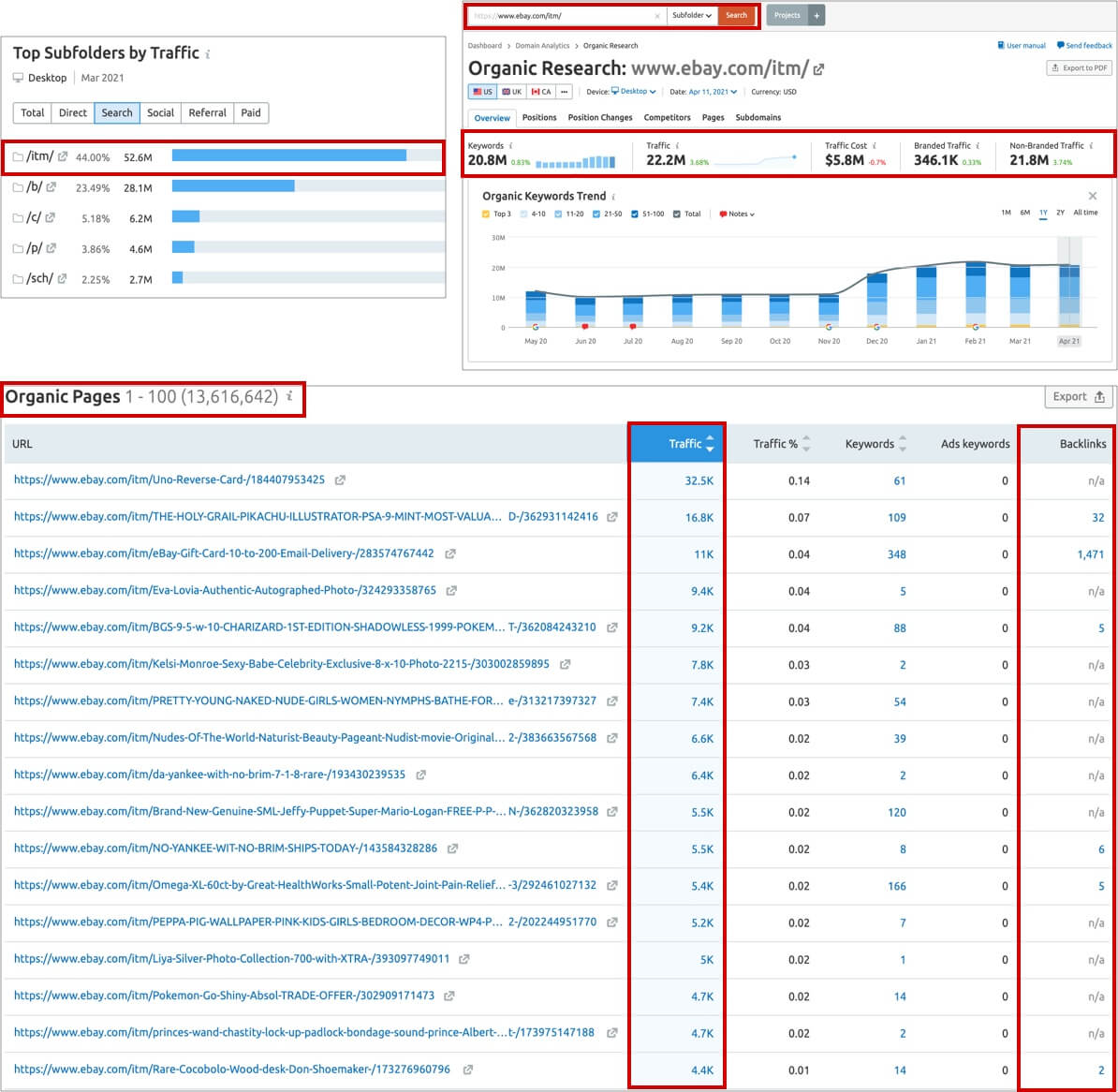
However, unfortunately is also not uncommon in e-commerce sites to see a high share of products pages left out from the Google index, and included among the “crawled – currently not indexed” and more specifically, excluded as products URls are identified to be “duplicates” of others, which although similar in nature, are actually pages featuring different products, but chosen as canonical by Google.
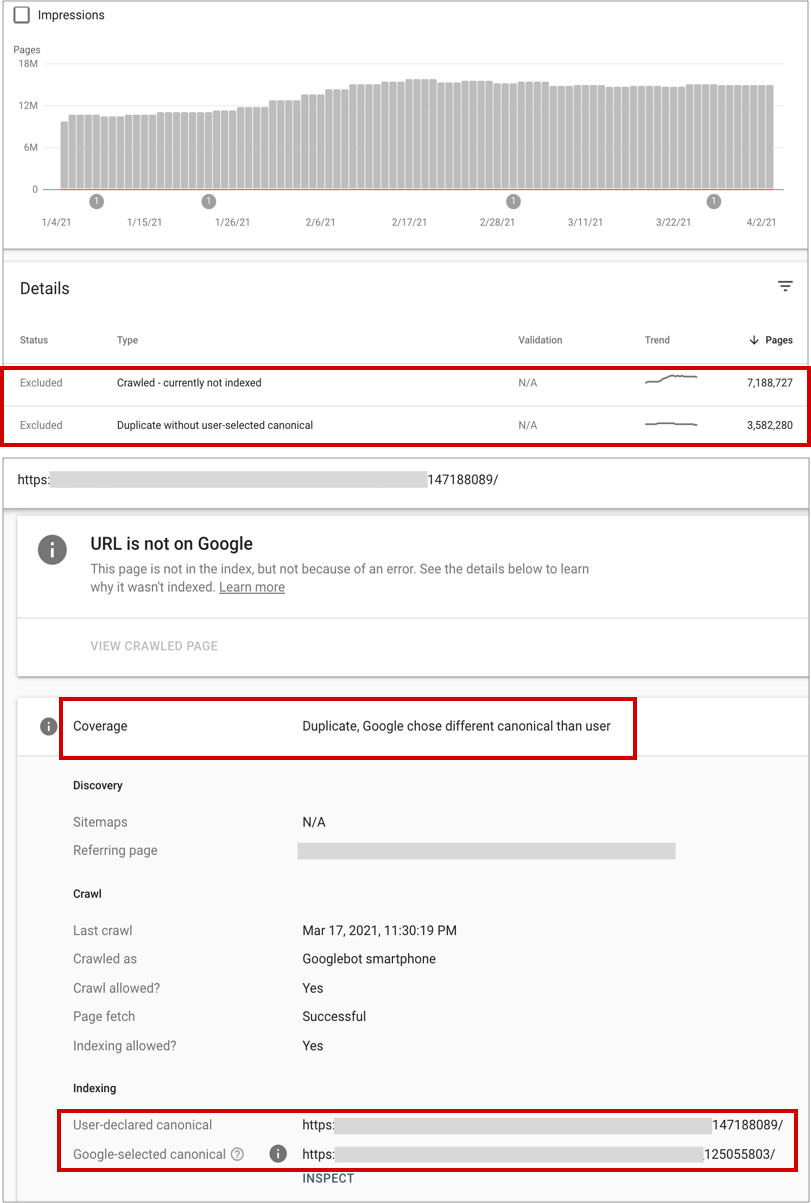
The first thing to make sure, -especially if you work with marketplaces where the products are not under the direct control of the store but uploaded/published by sellers directly-, is to avoid featuring the same product -or products with minor variants that are not popularly searched- in different indexable URLs, as on one hand, they will end up cannibalizing each other as they will feature the same (or almost the same) information, and on the other, they won’t target unique, different search queries, and therefore, not worthy to independently target with unique products URLs.
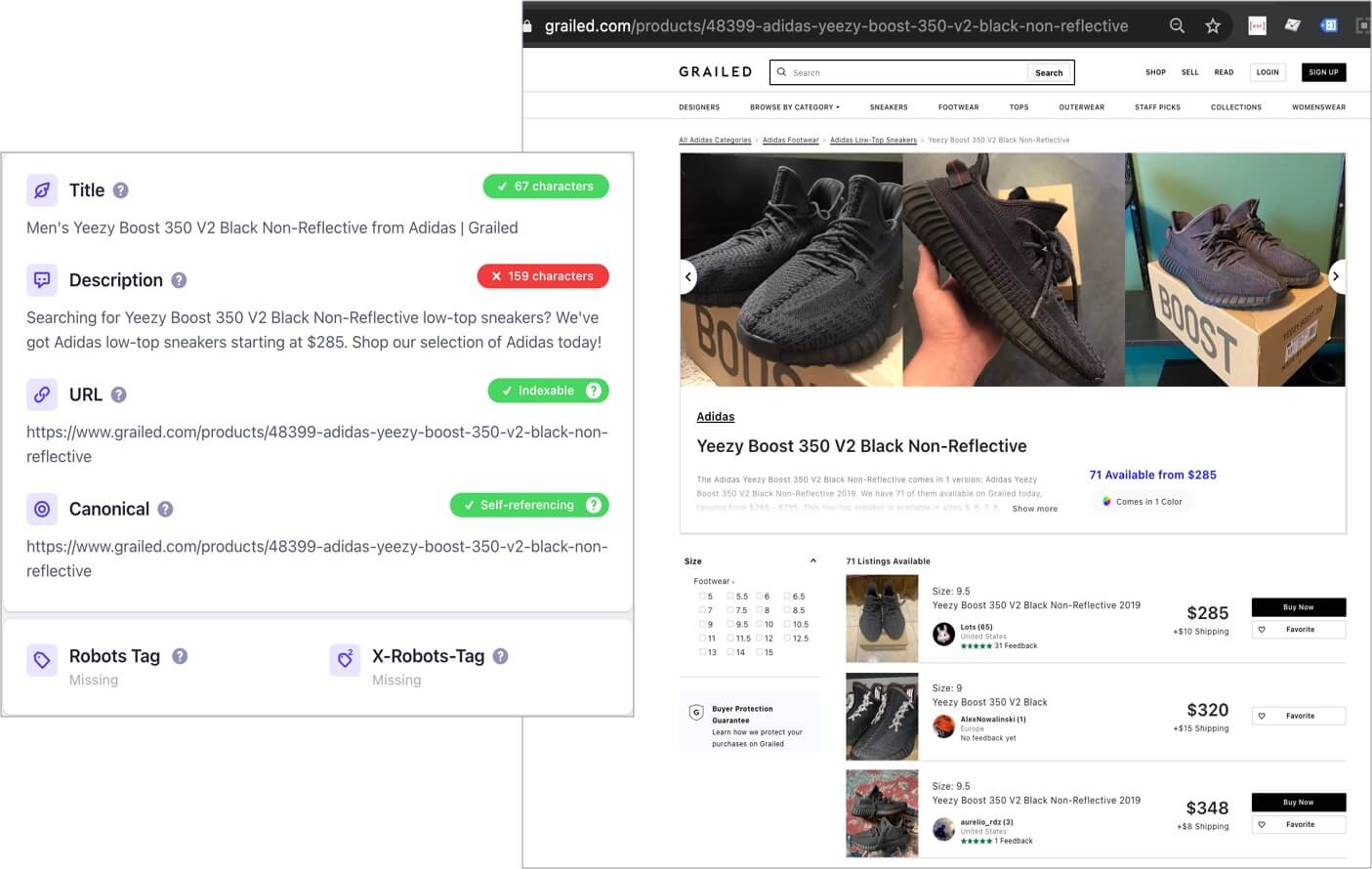
Instead, generate the different minor characteristics of the same products as features to be selected within the same product page. If you’re working with marketplaces, you can aggregate all the listings published of the same product in a single page, to avoid generating individual indexable URLs for each, while allowing to buy or bid for each independently, as sites like Grailed already do, and can be seen below.
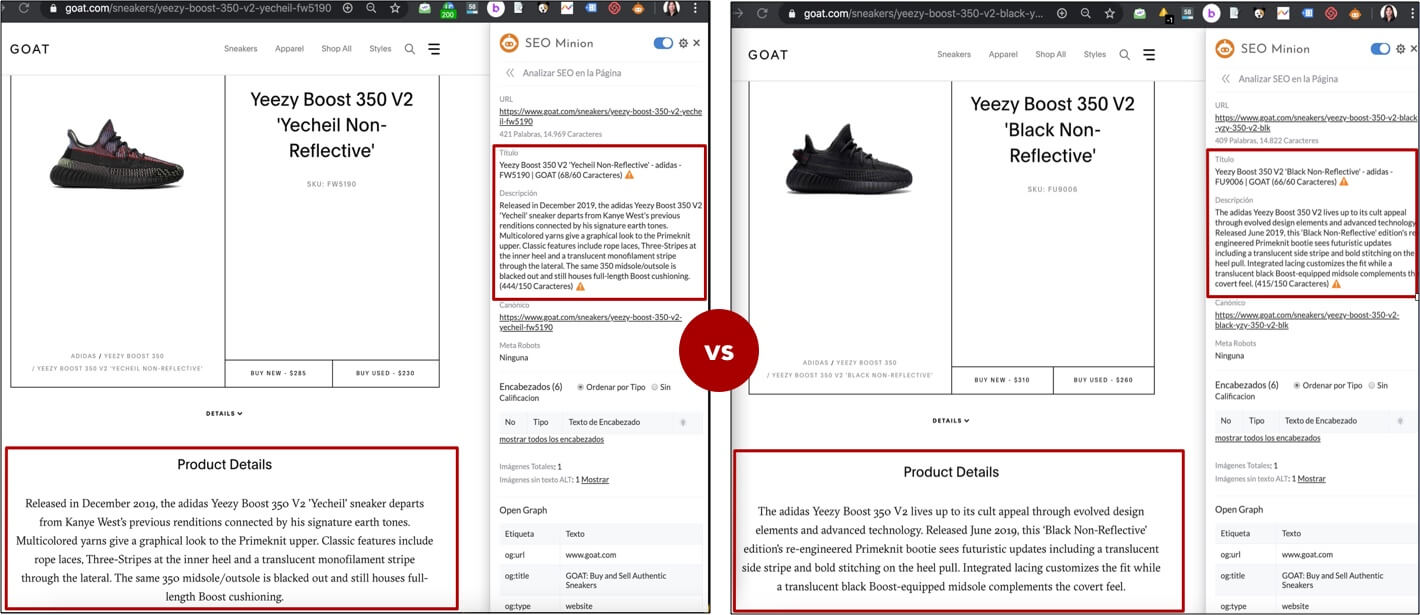
For those products pages which unique and meant to be indexed through their own canonical URLs, it’s fundamental to establish products pages content areas that can be optimized to become as relevant as possible to each product specific characteristics, starting with those that can be directly controlled and implemented at scale across all or most of them, like their metadata and descriptions, even if templated patterns are used, these can be defined to include: colors, sizes, models, target audience (men/women/children), etc. to start with a good base.
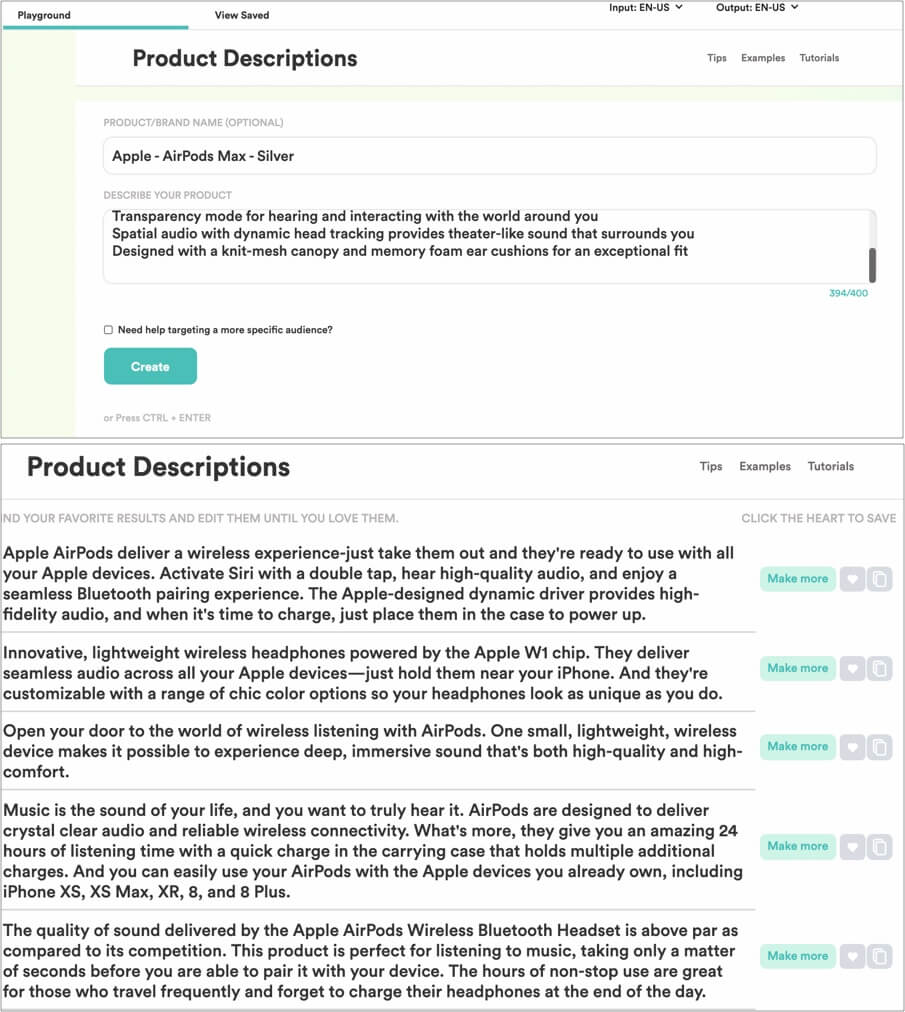
There are also now content generation tools like CopyAI, that can help to simplify the copywriting process, supporting (not replacing) copywriters and decreasing the required time to develop unique products descriptions at scale, as can be seen in the example below.
Additionally, it’s critical to establish mechanisms to develop your own products insights to feature in most popular ones, as well as to leverage user generated content (facilitating, incentivizing and gamifying users experience) to differentiate products pages further at scale, so they can become as useful and easy to use as possible to support the sales process:
- Comparisons with other models
- Users questions and answers
- Customers reviews and ratings
- Related / similar products
- Complimentary products
… as the most popular e-commerce sites already do with their products pages:
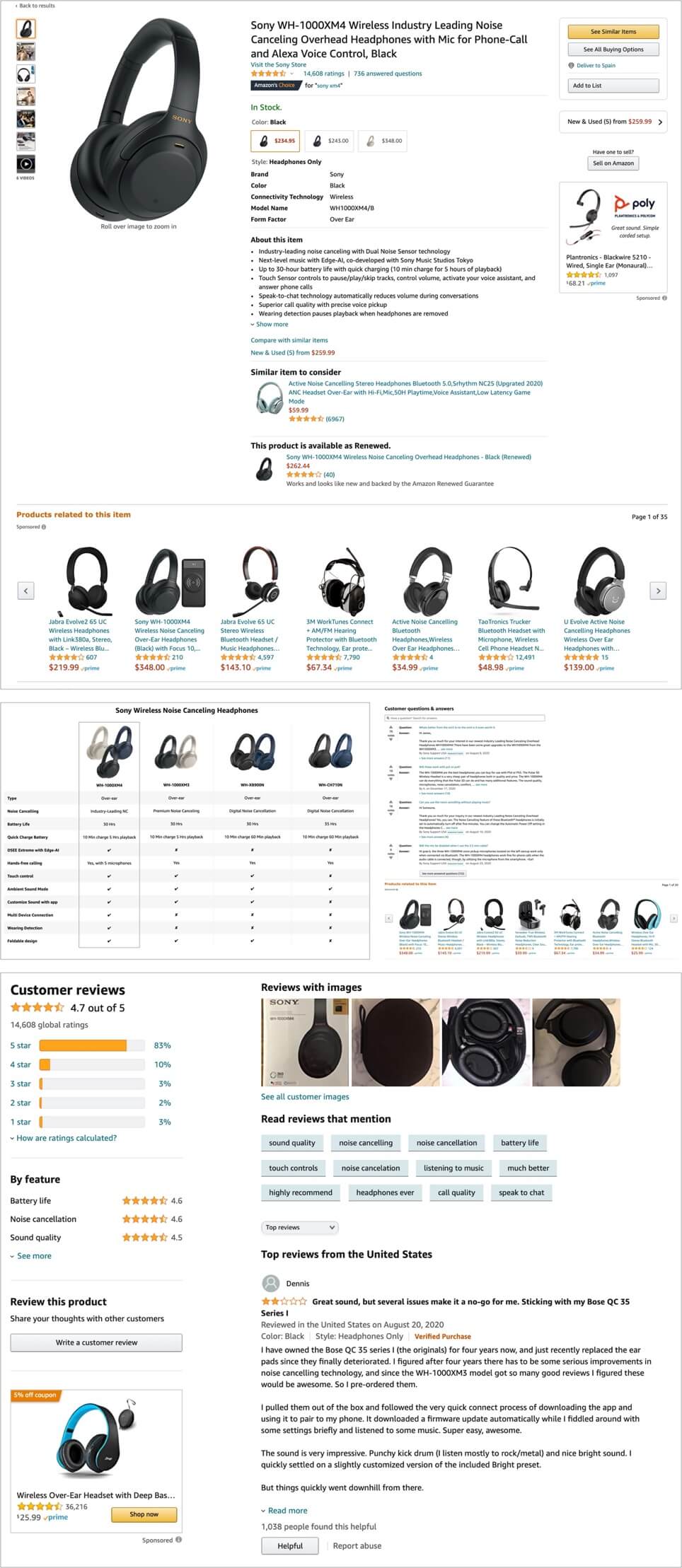
6. Highly Dynamic Product Pages returning errors or inconsistent status based on its inventory stage
Another common challenge of products pages is generated by their highly dynamic inventory, with changes of availability, without consistently updating their crawlability and indexability status, which cause that products URLs that attract non-trivial search traffic and links, end up showing status errors, losing their previous rankings, wasting their link popularity and giving a bad users search experience.
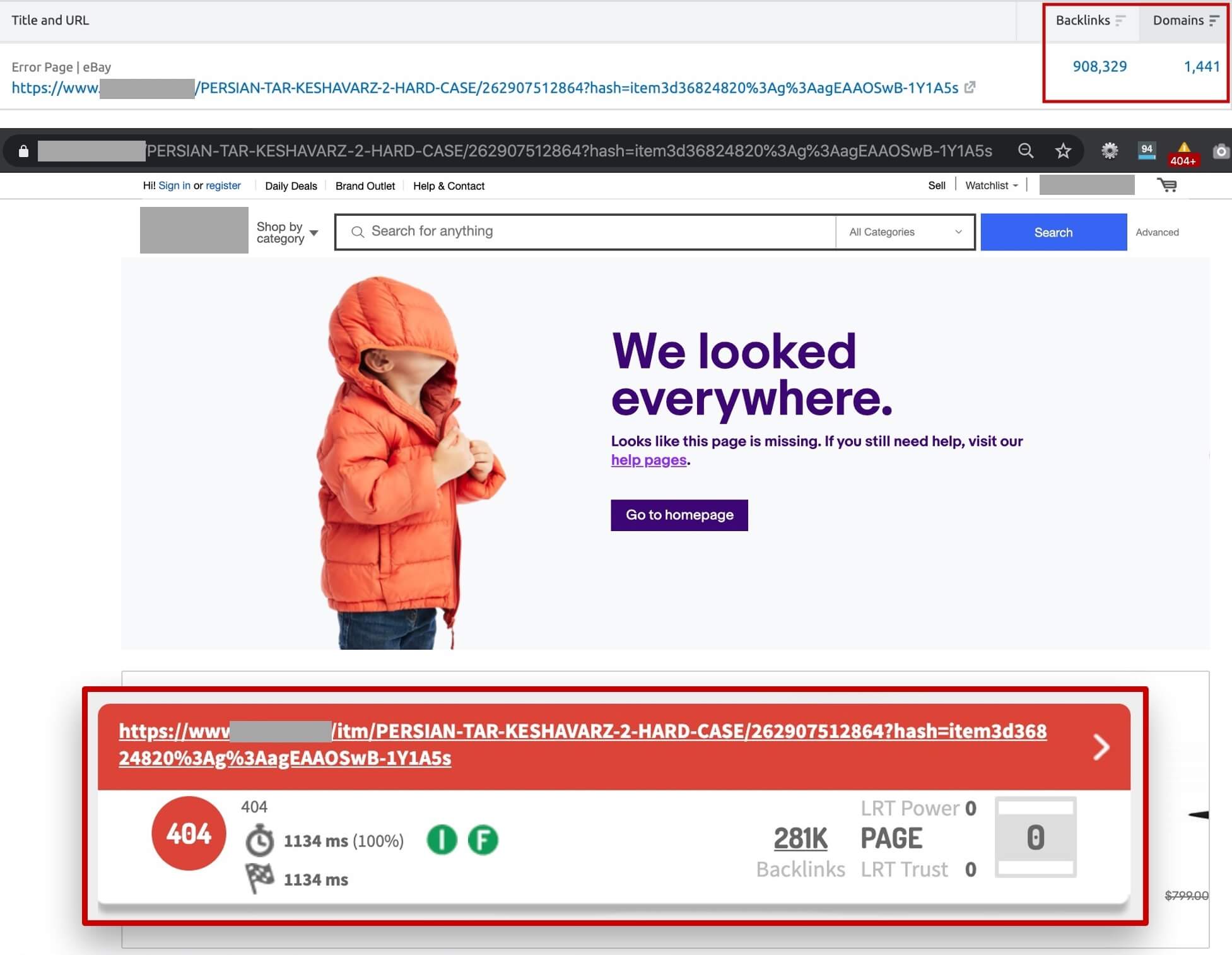
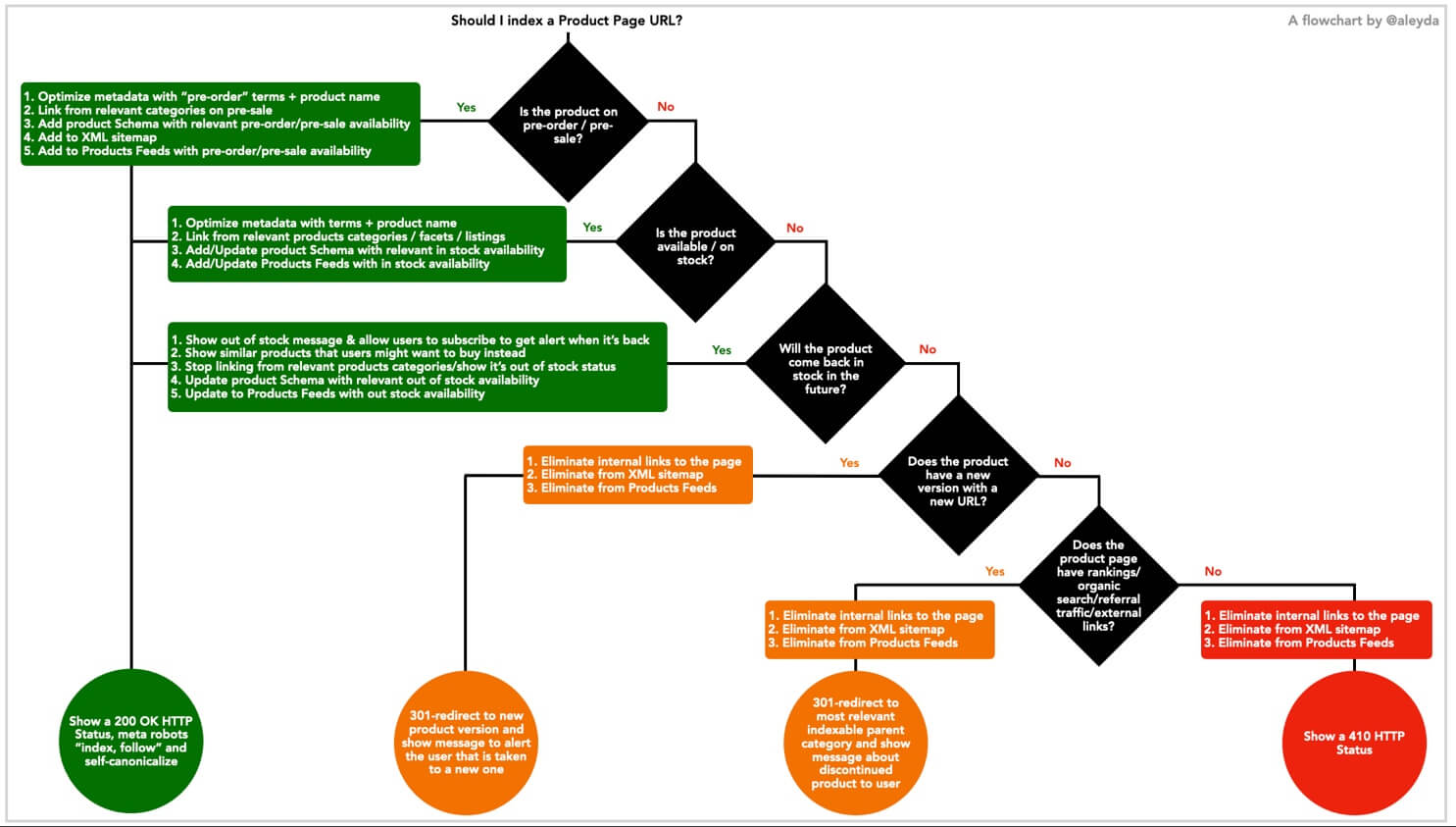
It’s then fundamental to establish rules within the Web platform to change the crawlability and indexability status of the products pages through their inventory cycle, and update their content, internal links, XML sitemap and products feeds inclusion as well as structured data accordingly:
- If the product is on pre-order / pre-sale: Show a 200 OK HTTP Status, meta robots “index, follow”, self-canonicalize, and…
- Optimize metadata with “pre-order” terms + product name
- Link from relevant categories on pre-sale
- Add product Schema with relevant pre-order/pre-sale availability
- Add to XML sitemap
- Add to Products Feeds with pre-order/pre-sale availability
- If the product is available / on stock: Show a 200 OK HTTP Status, meta robots “index, follow”, self-canonicalize and…
- Optimize metadata with terms + product name
- Link from relevant products categories / facets / listings
- Add/Update product Schema with relevant in stock availability
- Add/Update Products Feeds with in stock availability
- If the product will come back in stock in the future: Show a 200 OK HTTP Status, meta robots “index, follow”, self-canonicalize and…
- Show out of stock message & allow users to subscribe to get alert when it’s back
- Show similar products that users might want to buy instead
- Stop linking from relevant products categories/show it’s out of stock status
- Update product Schema with relevant out of stock availability
- Update to Products Feeds with out stock availability
- If the product has a new version with a new URL: 301-redirect to new product version, show message to alert the user that is taken to a new one and..
- Eliminate internal links to the page
- Eliminate from XML sitemap
- Eliminate from Products Feeds
- If the product page has rankings/organic search/referral traffic/external links: 301-redirect to most relevant indexable parent category, show message about discontinued product to user and…
- Eliminate internal links to the page
- Eliminate from XML sitemap
- Eliminate from Products Feeds
- If the product is permanently discontinued and doesn’t have rankings/organic search/referral traffic/external links: Show a 410 HTTP Status and…
- Eliminate internal links to the page
- Eliminate from XML sitemap
- Eliminate from Products Feeds
I’ve created the flow chart below (that you can see in a bigger version here) summarizing these different stages of the process, to make it easier to share with the relevant teams involved in their implementation:
By setting these rules, the crawlability and indexability issues generated at scale by a highly dynamic inventory of products pages should be minimized, you’ll be able to keep former products rankings, better leverage their attracted backlinks and more easily tackle specific “edge cases” by setting additional rules depending on your own context.
It’s time to minimize (easily?) preventable E-commerce SEO issues
I hope this article can help you to establish feasible ways to tackle some of the most common E-commerce technical and content optimization issues that you might have likely also recurrently identified in your SEO processes. What other problems do you find at a recurrent basis that are difficult to fix? Leave them in the comments!
![International Keyword Mapping & Content Optimization SEO Worksheet [Free Template]](https://www.aleydasolis.com/wp-content/themes/aleydasolis/imgs/flecha.svg)


