In the 16th episode of Crawling Mondays I go through the main criteria to take into consideration to prune your Web low quality content that can end up hurting your Website organic search performance.
You can also watch this video and leave a comment over YouTube. To follow more updates on Crawling Mondays, subscribe to the YouTube channel and follow to @CrawlingMondays in Twitter.
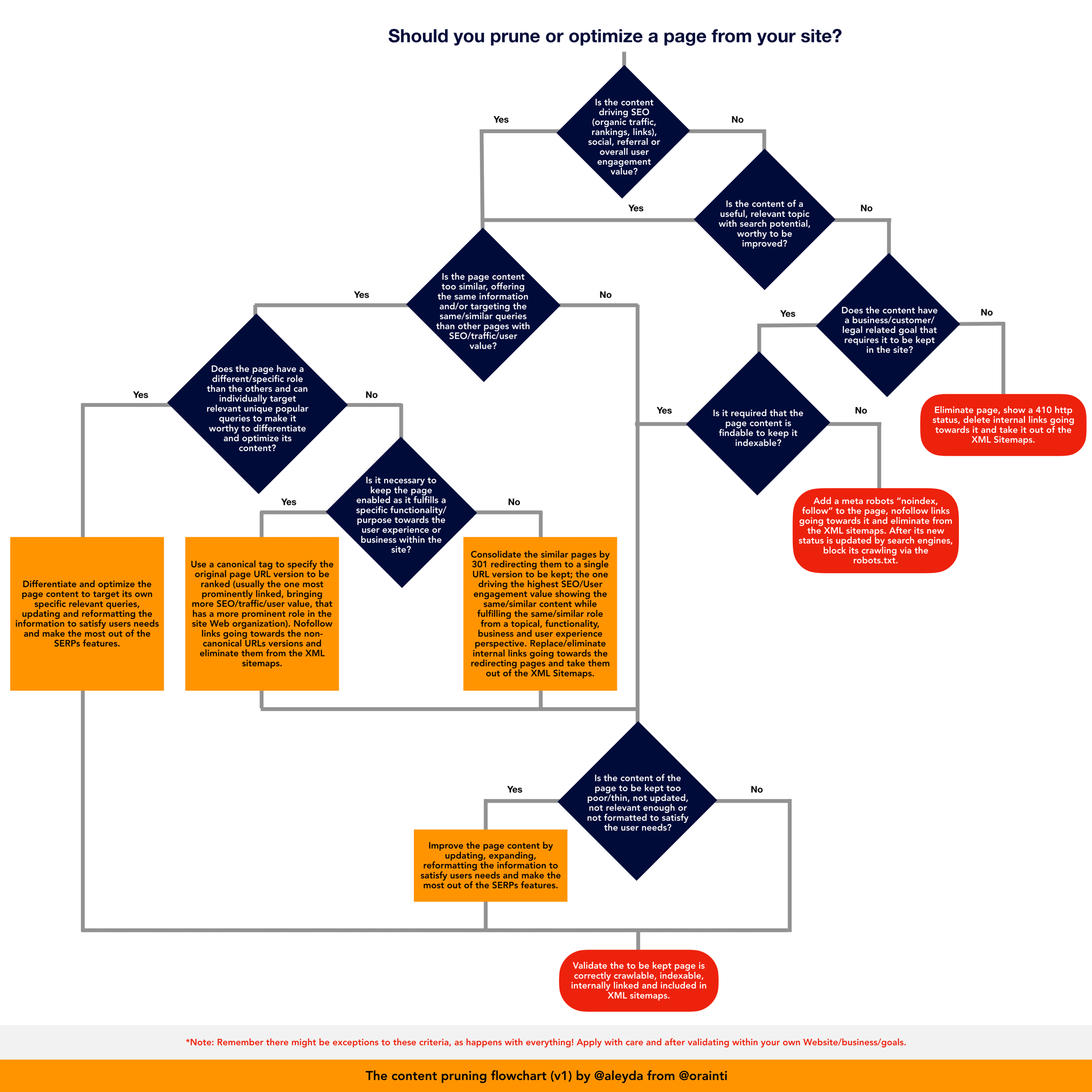
Here’s the Content Pruning flowchart shared in the video summarizing the top content pruning criteria and scenarios, which can be also seen in full size here:
Video Transcription
In today’s edition of Crawling Mondays I am going to focus on a very, very important topic, especially when doing an SEO process for big websites or websites too.
Content pruning: Content pruning in SEO well, you will see that there is a question that is asked again and again and actually I got the idea for this topic from Cyrus Shephard. Heads up to Cyrus and if you’re still not following him you should definitely do it up on Twitter. He’s always sharing really, really, really good SEO stuff and he did this poll.
When pruning all content, is it better to no index remove if you had a warm redirect to our relevant better page assuming that the content cannot be refreshed, improved, we should say, okay, if it is old content at some point we wrote should it be worthy to update, right and well not unless Holly, maybe it was very, very long ago, maybe we have another page that is very, very similar, same queries that might be much more worthy to keep. So there are so many different criteria and factors here that the usual answer is it depends, as with everything with SEO. And here my answers if you see here there were many SEOs who replied, “If that old content is not driving value traffic/ranking/links and is not working to improve update, not that relevant, not good potential topic, remove. But if driving traffic/rankings/links or could drive value if improved, then keep improve update or redirect to new version.”
Realistically, a content pruning process is not something will usually try value to improve the perception from a quantum-quality, quantum-relevance perspective of website, will also end up positively impacting the website total budget, in case we have a very large website that spends a lot of time crawling pages that are not really meant to be necessarily a rank anymore. It will end up having many effects in the rest of your process.
So, today I would like to share with you a little flow chart that I actually did, to try to simplify all of this if dense and, it depends, facilitate for you to go through the different type of scenarios and outcomes that this question usually has. So hopefully it will be highly valuable for you, as I expect it is, and I will be actually sharing this flow chart, also, on my blog, so you can share it, you can save it, and I will be also linking to blog posts from the video description to, so it’s far easier for you to get it so don’t worry. I will also be sharing how to actually go through all of these steps that I shared here, with the help of a few tools, gathering the data from all of this metrics that we are going to use as criteria by using certain crawlers, in this case first of all we’ll be using Deepcrawl and Screamingfrog, and using many other metrics that we will be gathering to do the best possible content assessment, to identify if we should prune, or optimize our page from our website. Let’s take a look.
Let’s start applying the questions. Should you prune or optimize a page from your website? This is the first question;
“Is the content driving SEO (organic, traffic, rankings, links) social, referral or overall user engagement value?” Right so this is the first question that we should answer. From all of these pages how many of this, which of those actually delivering any value, not only from an SEO perspective, because we are ranking, getting traffic, or attracting links, but that have an important role delivering any type of value from a user perspective. If they are not driving value, then we go to next step;
“Is the content of a useful, relevant topic with search potential, worthy to be improved?” Maybe they are not driving any value right now, but is it a very worthy topic, it has a good search potential, if not, again if the topic is not good, somehow we ended up losing something that is not that solid, that well relevant at this point.
“Does the content have a business/customer legal related goal that requires it to be kept in the site?” Like for example the legal [inaudible 00:04:28] and, or the privacy condition. If not, right, no I don’t even know why I have this content here because it has nothing to do… not potential topic, but not legal requirement, nothing to do with the business or legal side, operations side of the website, so in this case, yes, we can eliminate the page. We will show four-ten http status, and delete any internal links going towards it, and take it out, also from the XML sitemaps because this content is, just, consuming up our budget. On the other hand, we may have found that instead of replying with a no here, we reply with a yes. Yes it is a content, a legal notice that maybe it is not only a specific from a business perspective, it’s important from a legal criterion.
The next question will be; “Is it required that the page content is findable, to keep it index-able?” Right because maybe I should have it on my website because it fulfills some role, some type of role from a legal perspective, but it’s not necessarily required that it is actually findable by search engines. Users won’t actually be looking to search for this type of content, and if not, then it’s okay to not index this page. We can “add a meta robot ‘no-index follow’ to the page, and no-follow any links going towards it” because realistically we don’t want to send any value to these pages. If these pages are not fulfilling any important business rules that we want, that is findable, and they are not targeting any query also from a business perspective or important in the customer’s journey. So we very well can no-index.
“After its new status is updated, by search engines” no index and we see it’s not indexed anymore we can very well block it with the robot.txt so google doesn’t, or search engines in general they don’t spend time going through this page. In case there are many, right maybe this is not even worth it, if there is a very small number of them so it’s not really a huge consumption of our budget, however, if we are in a very specific scenario that there is a high number of this, we might just stop crawling them to stop consuming our budget.
Then on the other hand, we might answer with yes. “The content has a business/customer legal related goal”, and yes “It is required that it is findable”, right so we should keep it index-able within our website. If that’s the case, then we come here and we ask the next question;
“Is the content of the page to be kept too poor/thin, not updated, not relevant enough or not formatted to satisfy the user needs?” So even if it is not a page that is meant to be ranking for our top query, from the business side of our website or for a product service perspective, we will want it to fulfill very well its role. If it is too poor, too thin, then it is important to improve page content by updating, expanding, reformatting the information to satisfy users needs, and make the most out of the certain features, also if that’s a possibility. And then of course, “Validate that page to be kept is it correctly crawl-able, index-able, internally linked and included in the XML site map.” Since it is meant to be findable, it is meant to be index-able, it is meant to be searched, we should deliver the best possible experience right? In case that we find that the content is not poor, not thin, it’s good enough, update enough relevant enough from a counter perspective. No, then we should only validate and verify in this case that is technically correctly configured within our website. Then we go to the other side of the flow chart.
Is the SEO content actually driving value of any kind? And the answer is yes, so “Is the page content too similar offering the same information and/or targeting the same similar queries than other pages with SEO/traffic/user value?” If not, this page is targeting something unique featuring unique information/content or targeting a unique query, if not then we go directly and ask “Is the content of the page too poor/thin, can it be updated and improved”, and we follow the same steps. If yes we improve the content, we expand the content accordingly to make sure that it provides the best possible experience to the user and fulfills the user needs. And validate that it is correctly configured from a technical perspective that is correctly included in navigation and XML site maps, et cetera. And if not, we just validate the technical aspect, technical configuration of that.
If the page is actually targeting very similar terms than others, they are also index-able they are also driving value, then we should ask if the page has specific role than the others. If this page individually is targeting something unique, a relevant unique popular queries to make it worthy to differentiate and optimize its content. Maybe we can see that the content at this point is very similar but realistically it could be differentiated because the nature of the pages are actually different, or can be differentiated very easily. This other page can be tricked to be actually improved and differentiated well enough to target another topic that might be also very important for our website. If that is the case then it is worth to differentiate the content of these very similar pages, and optimize the page to target some specific queries and update it, formulated in a way that will actually fulfill the user needs, and to make the most out of the served features. Once we do this, we will again verify that it is technically correctly configured and that it’s correctly crawl-able, index-able, internally linked and included in the XML site map.
If we identify, however, that the page doesn’t have a specific role within the website, so it is featuring very similar content or duplicate content duplicating information at this point, it doesn’t make sense to differentiate it because it actually has the same role than another already popular page that is also driving value, then the question that we ask here; “Is it necessary to keep the page enabled, as it fulfills a specific functionality purpose that towards the user experience or business within the site?” And this is the type of role for example that some filters or facets may have. If these are used to change the number of items that are shown in our page, they will generate a new URL, doesn’t necessarily connect with an actual query made, but it does play a role with the user experience of our website. So we need to keep it enabled as a specific URL, that is actually accessible from a user perspective. But, we don’t necessarily want to go into this on the site because it’s not targeting any unique, specific queries that are worthy to rank for, so in this particular scenario we will canonicalize these pages to the original URL version that we identified. This is usually the one that is more prominently linked from within the website navigation, bringing more SEO traffic user value that has a more prominent role also in the site of our organization.
So we will canonicalize back to this original URL that we set, and also linked accordingly. We are going to follow the links going towards these non-canonical URLs, because they are not worthy to get any value, because they are not the ones meant to be ranked with the original ones as much as possible, eliminate them from the XML site maps. And once that this is done, then we should ask again the question “Is the content of the page that is kept” In this case, not the one of the pages that are canonicalizing, but the ones that they were canonicalizing to, the original canonical URL, “Is the content of the page to be kept too poor/thin, not updated, not relevant enough or not formatted to satisfy the user needs?” If yes, then we should again improve and expand, update the content to fulfill the user needs, and to make the most out of our features et cetera. And then again validate from a technical perspective that the page is correctly crawl-able, index-able, internally linked, included in XML site maps, and so on.
On the other hand, if the answer here is no, it is not necessary to keep the page enabled, it doesn’t fulfill specific functionality that required to be kept in the website, then we can consolidate these pages to a similar one and we can resurrect them to the one that we are going to select as the original, new updated one that we want to keep. So, “Consolidate the similar pages by three-hundred and one, redirecting them to a single URL version to be kept. The one that usually drives the highest SEO value, user engagement, value showing the same similar content or fulfilling the same similar role from a topic of functionality, business and user experience perspective.” Right, and we should “Replace, and eliminate any internal links going to this URL that we are going to be resurrecting.” The same, eliminate them from the XML site map, and again, once we do this with the content that is actually kept with the page (where these other URLs are redirecting to), we then should ask; “Is the content of the page that is kept” The final destination of this resurrect, “is it too poor/thin, not updated nor relevant enough nor formatted to satisfy the user needs?”
If so, we improve again. We then verify, validate all the technical configuration, okay, so as you can see I think that most of the most common scenarios in these content pruning journeys are included in this flow chart. So we can act accordingly, of course as I mentioned here in the note below, remember that there might be exceptions to these criteria as happens with everything. Apply with care and after validating within your own business goals, and this is just the first version. If you see that there is anything here that is actually worthy to be included, an important scenario that I haven’t included, please let me know I’ll be more than happy to include it.
I am going to show you how you can actually gather all this data and reply these questions very easily, thanks to a few tools. Of course, I want to show you how you can answer these questions from the flow chart in a versatile way by using SEO crawlers to crawl our website and integrate the additional metrics that will tell us what’s the value that they bring in to our website. So for this, we can use crawlers like Screamingfrog, as I mentioned before, or Deepcrawl, that I have here, and then of course complement this data the one that we can obtain from the Google Search Console for example. With the coverage report here, we can obtain which are those figures that have been excluded from the index, right. Why they have been excluded if they are index-able. These are the pages that are important for us to check, and of course we can gather data like this from the Google Search Console and do specific list crawls, with any of the SEO crawlers, to validate these specific pages.
It is also recommended that we do a full crawl from all of our website content to identify and assess all of the crawl-able URLs that we have on our site. This is what I have done already with remoters, which is my website project here, and as you can see we can easily integrate external data metrics that will allow us to answer the questions from the flow chart. So, from a traffic perspective Google Analytics, the Google search will be able to identify what are the rankings, the rankings of pages, the impressions that they are getting, et cetera. Then Ahrefs, for the link related metrics, to understand which of these pages are actually also being externally linked. Not only with Screamingfrog, but also I am going to show you with Deepcrawl, we can create data from the Google Search Console, Google Analytics, the back links, date from the site maps to identify the gaps too, and assess these pages again to prioritize the evaluation of these pages, and identify the lower performers. If we go here for example, for Deepcrawl or Screamingfrog or whatever SEO crawler that you use, and look for the team pages. Those pages are showing less content in general, and we can include and identify which of these pages have actually any organic search traffic.
Pages with duplicate content or very thin content, and identify which are the ones driving less traffic or with zero links. For example, that are index-able at the same time. Another important aspect is that any of these tools will allow us to export these pages along all of the metrics that we have gathered for them. For example, here I have the export from Deepcrawl, I can select these pages and tell me these figures are actually index-able, and are also duplicates, in this case none. And that have the lowest content to html ratio or that have the lowest text count in any of them, and exactly the same with the date that we can export from Screamingfrog, from all of these pages that I have exported, which of these are actually index-able and which of these have the lowest word count. So here I will reorganize a bit, and tell me which are index-able and have a very low word count, which are the ones getting zero GA sessions, zero traffic and zero links because again, I have the Google Analytics data here. I have the Ahref back links data here, zero links. So I can see all this by being index-able, have very little content, may have issues, and are delivering zero value from an organic traffic perspective, and rankings perspective. Start filtering, and at the end we can end up with this very specific set of pages that we can start here the worst performance.
We can see which are the very low performance and unfortunately these are the jobs type of pages that have indeed very little content because they have been generated in a very automated way, very little information. These are the lowest performance and it makes sense, in this case I should decide what do I do with this low performance, and we’ll follow the flow chart then. Is it worth for me? Yeah they aren’t driving much value right now, and the content is also too similar with all the job pages unfortunately. Yes, they do have a specific role within the website, and they should target individual queries, they should be worthy to target, and so ideally in this case I should differentiate, include and feature more content to fill this type of query.
Hopefully with these couple of tools and iterations you have been able to see how to gather this information, and to prioritize which should be the pages that you should be improving and which should be those that it’s not worthy for you to keep, and you can eliminate in a straightforward way. Of course if you have any questions, any doubts, if you want me to include any of the particular type of use case that you think might be valuable, just let me know. I’ll be more than happy to hear your thoughts about this, leave your comments, don’t forget, or tweet at me @aleyda follow me in case you still don’t follow me, for any reason, I’ll be more than happy to reply. Thank you very much, have a good day.



